Analysis
From raw data to insights — spot patterns, connect dots, and uncover what matters.
It pays off to invest some time into the setup of your research repository early on to get the maximum value. So if you are introducing Condens as a UX research repository in your organization this onboarding article will guide you through the main steps of the setup.
We recommend having one person who is responsible for the setup and who is the point of contact for questions about the repository in the organization.
Here is a checklist of the tasks which are explained in more detail below:
Also, check out this article about the six functions of a user research repository.
This first step is optional and won't be necessary for many organizations, but it significantly impacts the following steps of the setup. You can create multiple workspaces if certain projects and data should be stored separately. This option is typically used by agencies working with multiple clients or if in-house research teams have truly distinct streams of research. Read more about this option and how to activate it here.
An important step is to invite coworkers to Condens. There are different user roles depending on the level of involvement e.g. active collaborators or read-only stakeholders (see an overview of user roles).
We recommend inviting the people who actively collaborate on data analysis early on and do a joint kick-off to get everyone up to speed. Condens offers personal onboarding with all plans, so just reach out to us to schedule yours.
Before you invite stakeholders to the repository, import some data to avoid stakeholders come into an empty tool. Convincing coworkers of a new tool is a lot easier if they can immediately see something there.
Tip: To minimize the barrier of entry, you can use Single Sign-On so people don't need to create a username and password but can log in with one click.
Integrations support the efficient flow of data to and from Condens, ensuring that your repository fits into your existing landscape of tools.
While Individual integrations can be configured by every researcher individually and are only active for themselves, Workspace integrations are active for all researchers in the workspace and have to be activated by administrators. You can find a list of integrations and instructions on how to activate them here.
A useful research repository lets researchers and stakeholders find relevant information quickly. The way data is structured can facilitate or complicate that search for information. That's why we recommend taking some time to define how data is structured in your repository.
There are four dimensions to structure data in Condens: Projects, Participants, Artifacts, and Tags. We'll go through them one by one and explain how to adapt them to your organization.
These are the meta-data fields for projects helping to keep them organized and searchable. Thus the data fields on this level should apply to the entire project. Examples could be the research method, product area concerned, or country where the study takes place.
Project information fields apply to all projects and work as a template for newly created ones. Read about the details of using project information fields here.
These are the meta-data fields for participants. They help to both find research participants in the Participant Pool based on certain criteria and filter/sort data based on participant attributes (e.g. in global tags). Participant information fields can for example be used for contact information, profession, products used, persona, or experience level of a person.
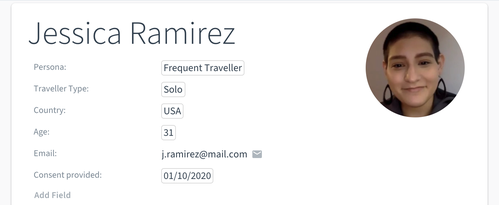
Participant information fields apply to all participants and thus serve as a template for newly created participants.
You can find more details on how to create them in this article about the Participant Pool.
Artifacts provide you with more freedom and flexibility when it comes to analyzing your research and sharing your insights. From independent atomic findings to detailed reports, you and your team can define the type of research outcome that suits your research results.
In your account, you’ll find an initial set of Artifacts, each with a different purpose: Report, Findings, Affinity Maps, and more, based on either a document-style Note or a Whiteboard.
When setting up your repository, it makes sense to create the Artifacts that you want to use in your workspace or optionally adapt the existing templates to your needs.
For example, you add structured artifact information fields. This helps to make research results findable, also for colleagues who are using the dedicated stakeholder repository with access to published Artifacts only. Examples could be the customer journey phase, mentioned products, associated departments, or demographic information of Personas.
Tags are used to categorize the actual research data. Specifically, Global Tags are those that are available in every project and thereby connect evidence across studies. We suggest that you set up a first set of Global Tags to start with and then reevaluate them in a few months.
If you're working in Condens as a team, you may want to have a short meeting to decide on the first set of Global Tags jointly. It’s important that everyone on the team understands the Tags and uses them consistently to get the best results.
If you want to upload your already existing taxonomy, you can read more about importing Tags from a CSV or Excel file here.
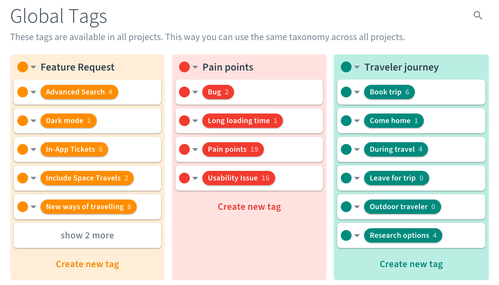
We highly recommend this article about building a taxonomy that explains the principles behind a good tag structure in detail and shows examples of other companies.
Tip: Do a review of the data structure after 2-3 months to reflect and improve things that don't work so well yet.
Folders are a powerful way to structure your repository by grouping related Projects. You can use Folders to categorize Projects based on product lines, teams, research topics, or other dimensions that align with your organization’s workflows. For example:
Group projects by research phase (e.g., Discovery, Validation).
Separate projects by department or business unit.
Organize projects for recurring studies, such as quarterly surveys or usability tests.
To create or manage Folders, navigate to ![]() Projects and click the button. This helps you maintain a clean, clutter-free repository and makes finding relevant research easier for your team.
Projects and click the button. This helps you maintain a clean, clutter-free repository and makes finding relevant research easier for your team.
With project templates, you can standardize how projects of a particular type look across your organization. A template is a pre-filled and pre-structured project you can quickly use when starting a new project. A project template lets you prepare a set of project tags, project information fields and descriptions, artifacts, and session templates.
Using project templates can help you to create consistency across projects, significantly reduce the need to manually duplicate structures, and ensures not to forget any necessary steps or data to add to the project.
Oftentimes, there is existing research data that should go to the repository to ensure there is one central place for research. We recommend following the two-step process below before importing past research.
Note: If you're switching from another repository tool to Condens, reach out to us and we'll help you with the migration.
Step 1: Which studies to import?
Firstly, it’s about deciding which studies to import. You can save a lot of time by disregarding those studies that are outdated and therefore irrelevant. Typically it's sufficient to only import those studies with a foundational character and thus a longer shelf life.
Step 2: What part of the study to import?
Next, you want to consider which parts of the data from a study you need. One option is to only import the findings as a PDF or presentation to the Artifact - all text within these files is searchable in Condens. Here’s a guide on how that works.
Importing only the findings into Condens is a lot quicker than importing all raw data, but doesn’t allow to tag or reference data in other projects in Condens.
If you decide to import the raw data, there are two options:
If available, you can upload the recordings and let Condens generate Transcripts of these. Then you can use the full functionality of Condens with tagging and video clips.
If you have the transcripts as text or just some notes, you can bring them into the Notes section of Condens with copy & paste. From here you can start to tag the text and build your Artifacts with Highlights.