
How to develop the right taxonomy for your UX research repository
There is growing belief that data gathered from user research is valuable beyond the scope of a single study. This is why UX researchers increasingly become orchestrators of information, responsible for storing data and insights in a retrievable way. And research repositories are the tools that support them in that task.
Depending on the respective goals a well structured research repository can:
- save a lot of time
- provide new insights from existing data
- fuel customer centric and evidence-based decisions in the organization
A robust tag structure - also referred to as taxonomy - is a central element of a repository. The goal is to organize information in a way that a good share of future questions can be answered quicker, with less effort and more precisely. An effective taxonomy helps to extract insights without having to go through every research session again or to conduct new research.
A lot of our customers approached us when they started their journey to build a repository and asked how to set up an effective taxonomy. This article provides some guidance and is based on the learnings we and other researchers have made.
Since every organization is different the ideal taxonomy also varies. A taxonomy that works great for one company might not make sense at all for another. That's why this article doesn't try to provide a "one size fits all" solution, but rather focuses on the underlying principles that help to develop a tag structure for your organization. This is covered in the first part of the article. The second part then shows best practices for managing tags before we look at some concrete examples of taxonomies in part three.
Before we start we should clarify one thing: What do we actually mean by a tag? In our understanding, a tag is used to categorize raw research data like statements from participants and observations.
Besides tags, there are other ways to structure data, like categorizing it by project or participants. While these are also important, we don’t call them tags and will cover them in another article. This article focuses solely on the structure of tags.
Also, we are focusing on the taxonomies of in-house researchers and teams here. Things might be different for freelancers and agencies doing research for multiple clients.
Principles behind a good taxonomy
We would love to simply tell you what the world’s best taxonomy is. You could copy it and we would be done here. Unfortunately, it’s not that easy. Creating a good taxonomy is difficult because it is very specific to an organization and also changes over time.
But there is also good news: There are some generally applicable principles that help you come up with a good taxonomy. You can think of these principles as those of the agile manifesto. They provide guidance but don’t impose a precise set of actions. Ready? Let’s dive in.
Principle No. 1: The right tag for the right purpose
Firstly, it’s important to understand that not all tags are created equal. In particular, there are two types of tags for different use cases.
Project-specific tags
Project-specific tags are only applied and accessible within the scope of a single study. They are often not defined up-front but created on the go as they emerge from the data itself following a process called grounded theory. When analyzing the data of a new research project, for instance, you don’t know much about the content of the data yet. Project tags help you make sense of it. You create them based on what the data tells you and quickly adapt them as your understanding grows.
There may also be cases when project-specific tags are created up front, for instance when they are derived from the research questions. In either case, project-specific tags are usually not applicable to data of other studies.
Global tags
Global tags, in contrast, are used across projects and thus allow researchers to connect evidence from different studies. A set of global tags is often defined up front and agreed upon in the team as the standardized application across projects requires a common understanding of when to apply them.
Global tags mark generally applicable observations that are valid outside the scope of a single project. That’s why they are used to track evidence of already known themes. For example, if a participant mentions a feature request on the currently released software version, this evidence is generally valid. It doesn’t matter too much from which study the evidence is from. A feature request on an early prototype, however, is much more limited in scope as the prototype isn’t in production yet. Thus a project-specific tag is the better choice.
Beyond the scope of proactive research projects, global tags are also used to categorize incoming feedback that comes from users directly or via colleagues from sales or support.
Project-specific tags
Global tags
Of course in a project both types of tags can come up at the same time. A good rule of thumb when to use which type of tag is to assess whether the tagged observation or statement is valid outside the scope of the current project or not. Also, project-tags tend to help understand and uncover new themes while global tags help to track evidence from known themes.
What makes creating a taxonomy difficult is largely related to global tags. On the one hand, they are an important component of a research repository as they elevate the value of existing data. On the other hand, they need to fit standardized definitions that work well across studies.
Principle No. 2: A taxonomy is in a constant state of change
A taxonomy is never done. It is not static but changes continuously. Project-tags typically change a lot in the beginning as one forms an understanding of the data. Global tags also change for example when the goals of the company evolve, teams re-organize or simply to test whether another tag structure serves the organization’s needs better.
The tag structure that you have now is most likely not the one you need six months or a year from now. Much more important than creating the (seemingly) perfect taxonomy right away, is to choose an environment where changing tags is easy. These changes include renaming tags, merging tags, splitting them up, bulk editing and arranging them in groups. Look for a system that offers this flexibility and you are set for a path of learning and iteration.
In addition, it helps if the repository supports everyone on the team to select the right tag and maintain consistency. Examples of this are smart suggestions for tags when text is highlighted, a fast search to select from existing tags and the possibility to add descriptions to tags.
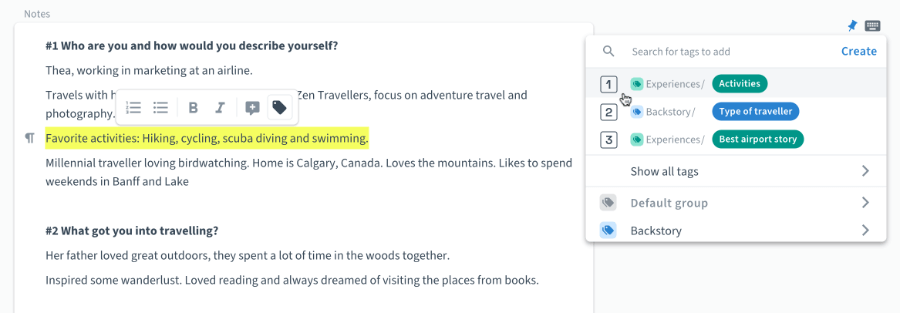
Principle No. 3: Start with the user
We learned that flexibility and constant iteration are key. But we still have to start somewhere, right? While project-specific tags often emerge from the data itself, global tags are different. So how do we define our initial set of global tags?
As with any design task we start with the user and the problem we try to solve for them. While you yourself may be the main user of the repository, your colleagues from research, design, product management or other functions will most likely be using it, too.
Questions you get
A good starting point is to look at the types of questions that users frequently have. If possible, collect and analyze them for the sort of information they ask for. Here are three examples:
- “What are the most frequently mentioned feature requests at the moment?”
- “Are there any usability issues for the search feature?”
- “We’re starting to create a new product for small and medium sized companies. What do we know about their pain points?”
The underlined words could all be tags in your taxonomy.
How your organization works
Looking at your organizational structure and how teams operate can also provide hints for tags. Let’s assume your organization creates a software tool that addresses four use cases and the product team iteratively works on them in cycles. Having tags for these use cases is a good start as you can provide the team with timely and precise information.
Another example: A food delivery company splits its product team by the core steps of the user journey: 1) Exploring food options 2) order and check-out 3) delivery. It’s likely that colleagues come to you with questions about the journey step they are working on. So having tags for the respective steps is helpful to filter for that information.
Other ideas for structuring your tags could be based on:
- How the research team is organized
- How the design or product team is organized
- The products or product categories your company offers
Guide: Building an Effective Research Taxonomy
Best practices for organizing tags
With the principles for a good taxonomy covered, let's now look at some concrete tips for the day to day work with tags. These are workflows and procedures that proved valuable across organizations and taxonomies.
Collection tags and specific tags
A common question is how generic or specific to be with naming the tags. For instance, if a participant makes a statement about a competitor would you tag it “Competition” or with the competitor’s name? One way to handle this is to start collecting all competitor evidence in a generic “Competition” tag that serves as a collector. Once in a while someone would then go through the tagged evidence and see if a certain competitor comes up more frequently. Only then a specific tag would be created for that competitor.
This approach prevents the taxonomy from having too many tags with only 1-2 pieces of evidence in them, but also allows you to search and filter for terms or topics that are mentioned frequently.
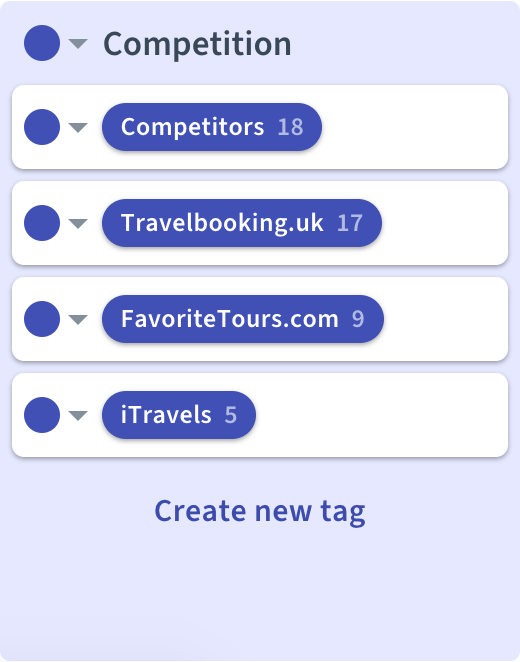
The same workflow can be applied to tags for other topics, like feature requests or usability issues.
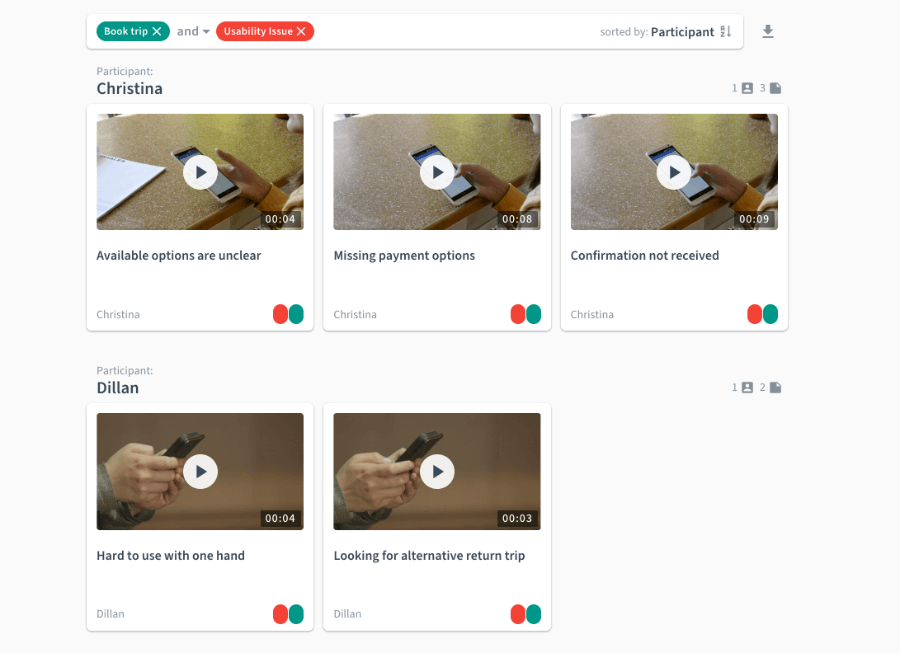
Multi-tagging to get different views
Adding two or more tags to a single observation allows you to categorize it from two different angles. For example you may want to tag user feedback by type (e.g. usability issue, feature request, bug) and the product area it concerns. This allows you to use combinations of tags for precise searches like “Book trip AND Usability issue”.
Track shipped features
When tagging for feature requests it is useful to have a second tag group for implemented requests. When a new feature has been shipped simply move the respective tag over to the other group.
That way the feature requests group stays up to date and isn’t cluttered with already shipped features. But instead of deleting the tag - which would also do the job - it lets you keep all the evidence regarding the implemented feature. You can still track future feedback for that feature and use it for future improvements.
Real-world examples
While a taxonomy is always unique to an organization it doesn’t hurt to learn from others and get some inspiration. We will now look at two examples of global tag structures that resemble what we learned from customers of Condens.
Taxonomy example 1: Software company with incoming user feedback
This company gets a large share of their research data from user feedback and sales or customer support.

Feature requests
The Feature requests group collects all ideas for new functionality that users share. The Feature request tag serves as a collector and there are additional tags for frequently mentioned specific requests. Next to that is a group for shipped feature requests.
Issues
This group hosts several types of issues. Pain points relate to anything that makes the jobs of the users difficult and are not related to the software the company offers. Data behind this tag is a good starting point for new features or products.
Usability issues, Bugs, Visual design directly relate to the use of the software. One specific usability issue got its own tag as it came up frequently. That’s the one the team is working on now or soon.
User journey
The research team also has tags for the most relevant steps of the user journey. These are often multi-tagged with feature requests and issues. They decided to only include five steps to keep the taxonomy simple.
It’s interesting to note that they chose generic tags for the user journey such that it works for both existing customers of the tool and non-customers who are proceeding through the journey without using the company’s software. This allows the team to capture research data for non-users (e.g. pain points) and users (e.g. feature requests).
Product evaluation
This group holds tags that capture insights and feedback from prospects before they purchase the tool. Some of the tags are inspired by a customer acquisition framework that focuses on 4 forces that influence a customer switch.
Taxonomy example 2: Software company with proactive research and incoming user feedback
This company has an equal share of active research studies and incoming feedback through sales and support. Their software tool provides solutions for several use cases.
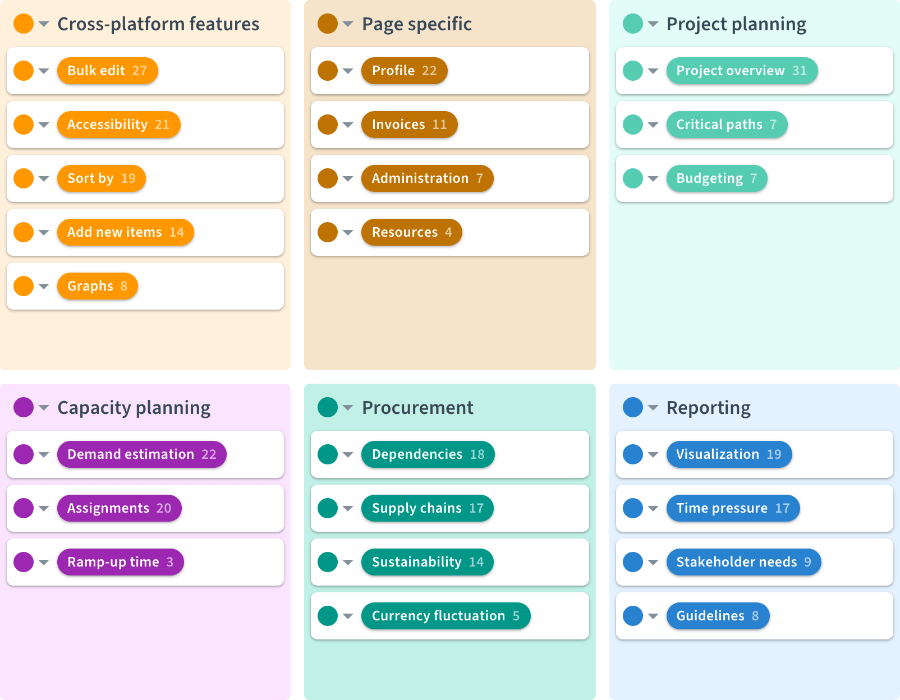
Cross-platform features
In this group they collect feedback and observations on features that are not unique to a single web page or use case but span the entire product like Accessibility or Bulk edit.
Page specific
Here is where they track evidence that relates to a specific page of their software. The product team often works on one page per cycle and with that tag structure they can easily filter for research evidence about the respective page. The research team frequently uses tags from the Cross-platform features group together with tags from the page specific group to combine views e.g. “bulk editing on the invoices page”.
Use cases
Lastly they have a tag group for the four major use cases their software supports. The individual tags represent concrete concepts or topics within that use case. The evidence in this group also includes more fundamental findings that are not necessarily related to the product.
Want to read more? Check out our articles about what a UX research repository can do for you(opens in new tab) and the design considerations behind a research repository(opens in new tab).
